
Practical Challenges of Imitation Learning from Observation
Overview
In this post, I will explore some practical details in popular imitation learning from observation methods. Learning from observation (LfO) is the problem of learning a policy from a set of state-only expert demonstrations. The goal of LfO is to eventually enable agents to learn by observing humans or other robots. However, LfO is difficult because it both requires learning perception of what the expert is doing, and then learning a control policy on top of this learned perception. We cannot directly apply standard imitation learning approaches like Behavioral Cloning or Generative Adversarial Imitation Learning [2].
Popular LfO methods adapt the standard imitation learning algorithms for the case of having no actions. Behavioral Cloning from Observations (BCO), first learns an inverse model from agent experience, and then uses this to infer the missing expert actions and ultimately perform standard Behavioral Cloning (BC) [1]. Generative Adversarial Imitation from Observation (GAIfO), adapts Generative Adversarial Imitation Learning to LfO by learning a discriminator from state, next state pairs rather than state, action pairs [3]. GAIfO-s is another method sometimes used in practice, which changes the GAIfO discriminator to only take a single state as input [4].
In this post, I will share my experience training BCO, GAIfO, and GAIfO-s. Hyperparameters and implementation details are important for these algorithms. I use the HalfCheetah-v3 environment from OpenAI Gym to show how the algorithm details affect performance. In all sections, the expert dataset is 50 episodes of 1k steps with 6678 average reward on the HalfCheetah-v3 environment.
BCO
In my experience, the biggest pitfall of BCO is when the policy cannot produce meaningful experience for the inverse model to learn from, resulting in bad action inference on the expert dataset. If the policy begins to produce bad data, the inverse model and policy can get stuck in a bad cycle. The inverse model predicts bad actions, which results in a bad policy, which results in bad experience for the policy, and the cycle continues.
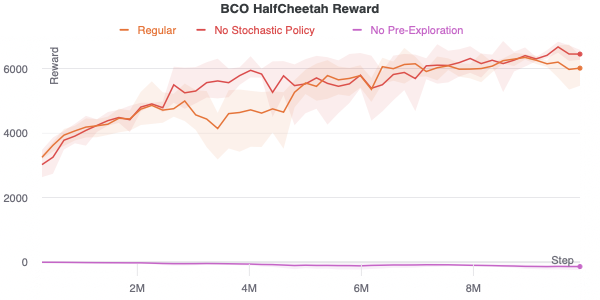
All this means that BCO struggles in problems where a decent inverse model cannot be learned from random exploration. While updating from additional policy data can help, it needs a “good foundation” to start from, or the policy will never have good data to learn from. The importance of exploration and good data for the inverse model leads to two important hyperparameter considerations.
Pre-exploration: There should be a phase before policy learning where a random policy collects data to train the inverse model. Collecting data with only the untrained policy will not be random enough to get meaningful diverse data for the inverse model.
Stochastic Policy: The policy should output a distribution over actions. Increasing the stochasticity of the policy increases the diversity of data for the inverse model.
Below are plots comparing these hyperparameters. While the stochastic policy does not matter for HalfCheetah, I experienced that it is necessary for learning in more complex control tasks like pick and place in robotic manipulation. Its little effect in HalfCheetah could be because exploration is easy and the task is repetitive. The table of hyperparameters used for this plot is below.
| Hyperparam | Value |
|---|---|
| $\alpha$ (num updates) | 50 |
| Inverse model architecture | (400,300) |
| Inverse model learning rate | 3e-4 |
| Inverse model learning rate decay | No |
| # epochs per inverse model update | 1 |
| BC policy architecture | (400,300) |
| BC learning rate | 3e-4 |
| BC learning rate decay | No |
| # epochs per BC update | 10 |
| State normalization | Yes, from expert state data |
| BC stochastic policy | Yes, learned mean and standard dev for norm dist |
| # random exploration steps | 200k |
| total # environment steps | 10M |
GAIfO
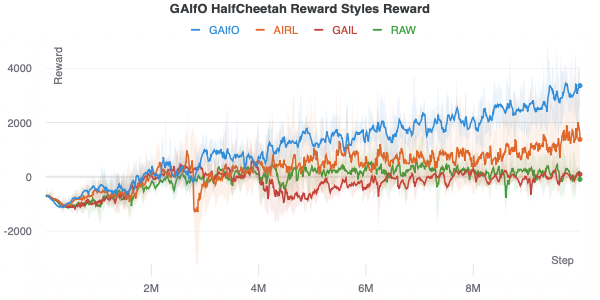
Reward Type: Since GAIfO relies on adversarial training it can be very sensitive to hyperparameters. Most surprising to me was the importance of the reward function implementation. There are several ways you can implement the reward function in adversarial imitation learning methods (where $ D(s) $ is the discriminator with a sigmoid output):
- AIRL: $ \log D(s) + \log (1 - D(s))$, expert with label $1$ [6].
- GAIL: $ \log D(s) + \log (1 - D(s))$, expert with label $1$ [2].
- Raw: $ D(s)$, expert with label $1$.
- GAIfO: $ \log D(s) $, expert with label $0$ [3].
The fourth choice is what the GAIfO paper uses. Note that this is a different reward than what popular GAIL codebases use [5]. Using the correct GAIfO reward is crucial for learning. Below are the different rewards in HalfCheetah. All the hyperparameters except the reward type are fixed across runs. Interestingly, some reward types struggle to learn.
| Hyperparam | Value |
|---|---|
| Policy architecture | (400,300) |
| Policy optimizer | PPO |
| PPO entropy coefficient | 0.001 |
| Policy learning rate | 0.001 |
| Policy learning rate decay | Yes |
| Discriminator architecture | (400,300) |
| Discriminator learning rate | 0.001 |
| # of discriminator updates per policy update | 2 |
| total # environment steps | 10M |
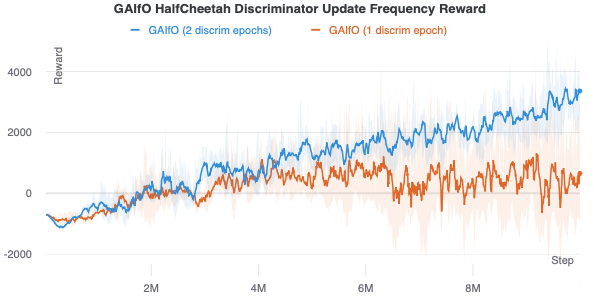
Another important consideration is the discriminator should be updated more frequently than the policy. By updating the discriminator more, it will be a better fit for the current on-policy state distribution, providing a better reward. A comparison of 1 versus 2 discriminator updates per policy update is shown below.
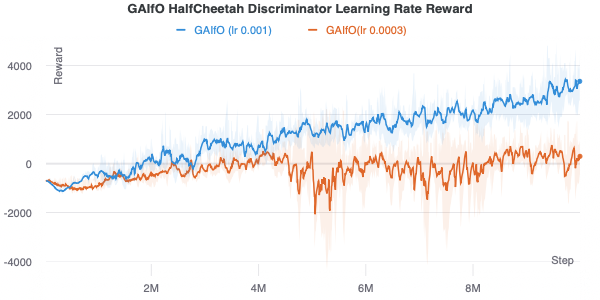
Since a discriminator accurate for the current distribution of policy data is important, a higher discriminator learning rate is important as well. As shown in the figure below, a lower learning rate results in poor performance.
Finally, while maybe obvious, it’s important to have a high discriminator and network capacity. The below figure compares using a policy and discriminator network architecture with hidden layers of size (400, 300) versus (64, 64).
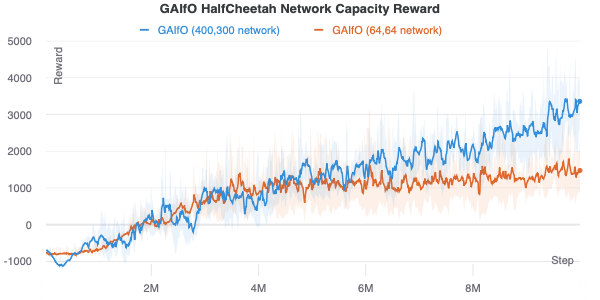
GAIfO-s
Intuitively, GAIfO-s should perform worse than GAIfO because it only has access to a single state and therefore cannot infer dynamics. However, I have found that GAIfO-s performance can be better than GAIfO when the state includes temporal information such as velocity. In that case, a single state is enough to infer dynamics information. While GAIfO performs better than GAIfO-s in HalfCheetah, I have found the opposite to be true for harder tasks in robot manipulation.
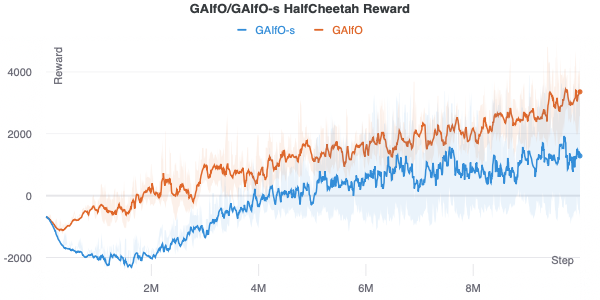
Takeaways
- Have an exploration phase in BCO where a random policy collects data.
- Use a stochastic policy in BCO.
- Use the correct GAIfO reward type from the original paper for GAIfO.
- The discriminator should learn faster than the policy in GAIfO. This means increasing the discriminator learning rate and updating it multiple times per policy update.
- Use large networks. This will vary by task, but this is often an issue I forget about.
- GAIfO-s can work well for some problems.
References
All plots were made with W&B.
- [1] Torabi, Faraz, Garrett Warnell, and Peter Stone. “Behavioral cloning from observation.” arXiv preprint arXiv:1805.01954 (2018).
- [2] Ho, Jonathan, and Stefano Ermon. “Generative adversarial imitation learning.” Advances in neural information processing systems. 2016.
- [3] Torabi, Faraz, Garrett Warnell, and Peter Stone. “Generative adversarial imitation from observation.” arXiv preprint arXiv:1807.06158 (2018).
- [4] Yang, Chao, et al. “Imitation learning from observations by minimizing inverse dynamics disagreement.” Advances in Neural Information Processing Systems. 2019.
- [5] Kostrikov, Ilya. “pytorch-a2c-ppo-acktr.” (2018). https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail
- [6] Fu, Justin, Katie Luo, and Sergey Levine. “Learning robust rewards with adversarial inverse reinforcement learning.” arXiv preprint arXiv:1710.11248 (2017).