
Voice Conversion
How well can we convert speech between people’s voices?
By: Andrew Szot, Arshdeep Singh, Md Nasir, Sriram Somasundaram
Introduction
Recently, there have been many exciting results in computer vision with the introduction of deeper convolutional models that encode higher dimensional and interpretable features (neural style) [1]. In contrast, deep and thorough understanding of speech has suffered from the lack of deep learning models catering to audio signals. For a while, traditional audio processing techniques remained dominant over deep learning approaches in terms of audio classification and detection. Specifically, generative models in audio were just until recently dominated by traditional audio processing techniques. Rather than using a deep learning model, many of the generative models would piece together the correct speech fragments stored in a large database, while some others use traditional features fed into a deep learning architecture. End-to-end deep learning has been a rarity in speech applications due to the fundamental characteristics of temporal structure of speech which contains so many different informations crammed together–speaker characteristics (voice), linguistic content (language), paralinguistics (emotion and behavior). Several new generative audio deep learning models such as Tacotron [2] and Wavenet [3] have brought change to this situation. A good amount of research has already been done into how these models can be used for text to speech (TTS), speech generation, or speech classification.
Our initial motivation was to see whether a good (our criteria below) latent space model for raw audio could be generated and used to do audio style transfer, drawing inspiration from the neural style algorithm. Neural (image) style transfer is a famous application of convolutional networks where style information is encoded in shallow layer activations and content information is encoded at deeper layers that have global context. The algorithm takes the correlations of style filter activations into a Gram matrix to discard spatial information past local textures.
We were curious if this same idea could be applied to the audio domain. Specifically, we choose to pursue a subset of this problem, voice conversion.
Voice conversion is taking the voice of one speaker, equivalent to the “style” in image style transfer, and using that voice to say the speech content from another speaker, equivalent to the “content” in image style transfer. We choose to focus on voice transfer because it was a well defined but relatively unexplored problem. There have been investigations in style transfer with combining the two sounds of instruments as seen with Google’s NSynth [4]. We thought that voice style transfer would be easier to evaluate, and voice conversion is a more challenging problem as voice is a harder feature to encode in a model’s latent space. This is an interesting problem to tackle both from a technical and social perspective and could have applications in music industry, legal affairs, robotics, automated talking devices, and more. Our approach was to be able to perform voice transfer on non-parallel data.

This means that the style voice could be saying something completely different than the content voice. We hoped to design a model that could learn a latent space encoding higher dimensional information in audio and would be able to generalize the style voice without necessarily being trained on all possible phonemes (smallest unit of speech) that could occur in the content voice.
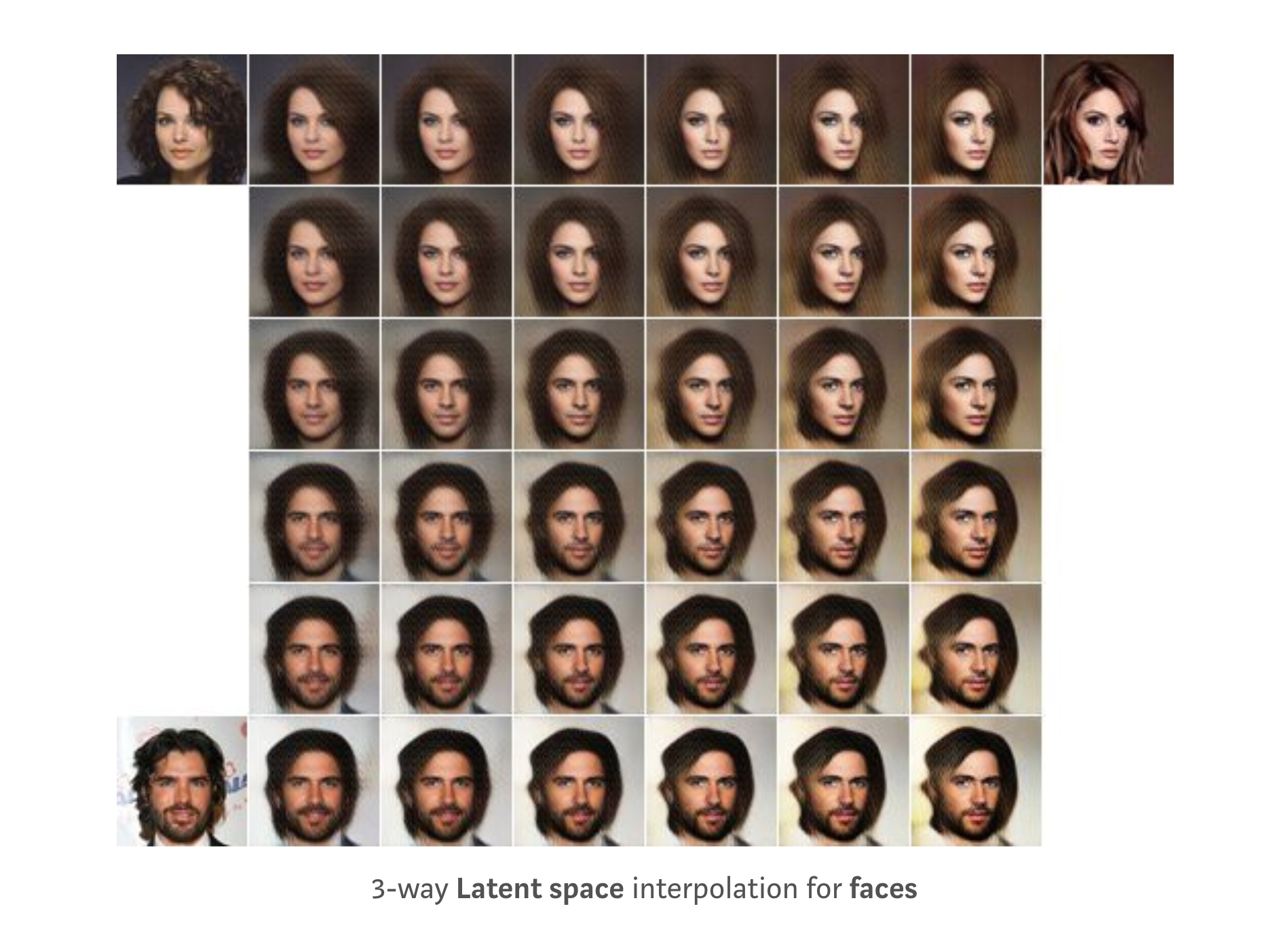
Just as linear interpolation in the latent space for facial recognition encodes changes in facial structure, movement in an audio latent space should encode an audible changes in the higher dimensional features of audio (phones, style).
Overall, this problem is important to address both on an application and theory level. On an application level voice transfer would enable voice-assistants of all different styles. You could even create a voice assistant that had your own voice. Even though models such as Tacotron already exist, our approach to voice style transfer would reduce the amount of training time needed as the model does not explicitly need to pick up on every annunciation of each phoneme as it can generalize. On a theory level voice style transfer would give a lot more insight into the power of embeddings and how to find them for data. Working with raw audio is far more challenging than images. The length of the audio is variable and the structures in the raw audio are far more abstract. Learning an embedding for speaker style would be a significant advancement in learning embeddings in general.
There are currently not many approaches to this problem, and existing approaches can be broken into three categories: spectrogram processing, supervision to extract content and apply style, and models with an unsupervised latent space. Each of these approaches has encountered significant problems and fails to produce any good sounding results. Most of the results sound very robotic and do not resemble the original style at all or simply turn out to be white noise. Another issue with the current approaches is that the approaches that do get decent results are using a lot of supervision and use complex datasets. For instance, an approach that gets decent results requires a lot of data for each speaker and also requires the target phonemes for each sample. The motivation in our approach was to provide a completely unsupervised method that could work on non-parallel speaker data.
Approach
We divided our efforts into 4 approaches as a result of our progression through the field:
- Spectrogram approaches. The approaches in the frequency domain of audio (spectrograms) usually involve existing image style transfer techniques on spectrogram images. However, those techniques cannot extract local information regarding phonemes for speech and are better at recognizing global recurring frequencies in music. To try out a model using spectrogram data, we took on the novel task of training a CycleGAN between collections of male and female audio as our baseline.
- Supervised latent space / Unconditional generator. After talking to our mentors, they suggested that some degree of supervision for text or phonemes might be useful to try out in the latent space. As a result we tried as 2-step model that included a supervised Speech recognition encoder and a Tacotron decoder for speech synthesis. However, the text to speech module for decoding was not conditioned on speaker and had to train on lots of audio from a certain style speaker (unconditional generator).
- Supervised latent space / Speaker conditioned generator. Based on our previous approach, we wanted the quality of results that came with supervision yet wanted to move closer to our original goal which was to be able to extract information from only a few samples of the style speaker. As an intermediate step, we tried a model with a generator that was conditioned on speakers.
- Unsupervised latent space / Speaker Conditioned generator. Finally, we attempted to newly implement ideas in a fresh Deepmind paper in the audio domain with an unsupervised latent space. We implemented Auto Encoder variants (VQ-VAE, full Wavenet autoencoder).
Data
We trained and evaluated almost all of our models on the CSTR VCTK Corpus [6]. This dataset contains speech data for 109 English speakers saying 400 sentences each. Utterances are saved as WAV files and are 4 to 10 seconds long. While data is text annotated and parallel, we didn’t use these features in our unsupervised models. Furthermore, we never performed frame alignment to achieve truly parallel data.
We used the TIMIT [7] dataset for supervised Speech Recognition encoder + Tacotron decoder that includes 630 speakers each reading 10 sentences. The dataset contains time-aligned phonetic and word translations that are useful for supervising the encoder.
We also used the Arctic dataset for many audio samples from a single speaker to evaluate the supervised model.
Baseline: CycleGAN
Our first approach tackled the problem from the frequency-domain representations of raw audio. There has been previous work in applying the neural style algorithm (for images) onto the spectrograms of content and style audio [8].
Results seem to be a mash of the content and style audio and speech style transfer (voice conversion) will not work as easily due to the absence of identifiable and common frequencies across the audio sample. In general, a style algorithm relying on the Gram matrix of the spectrogram of the style audio will lose time information and just involve correlations between frequencies that are drawn from a small context. For voice conversion, we care about local statistics rather than increasing consistent frequencies. Furthermore, only operating on one sample for style does not provide a very good description of the overall style for that speaker and would theoretically only work best in the parallel audio case.
As inspiration we saw how CycleGAN [9] had been applied to the image domain and wanted to apply the same to the audio domain. For our setup we had set $ X $ contain male voice samples and set $ Y $ contain female voices samples. We figured that this approach was a trivial enough application of an existing model to be considered a decent baseline. The architecture for CycleGAN is shown below.
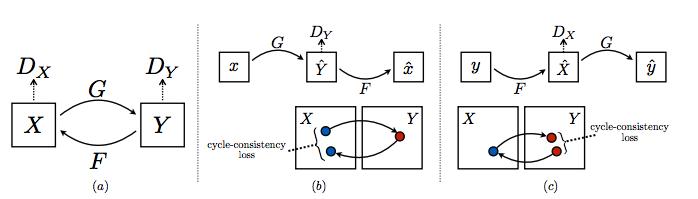
We split the VCTK dataset into male and female audio collections and applied a short-time fourier transform (used Librosa [10], an open-source Python library for a lot of audio manipulations) and padded to form a 3-channel image of 256x256. We trained a CycleGAN in Tensorflow (https://github.com/ASzot/voice-conversion/tree/master/cycle-gan ). The core concept of CycleGAN is performing a translation between sample $ A $ from domain $ X $ to sample $ B $ in domain $ Y $. A key concept of CycleGAN is that this translation is constrained by the fact that the the inverse mapping must undo the translation. This is referred to as cycle consistency. A big advantage this provided us in our project was that this model was no longer constrained to parallel data and could learn to generalize the transformation across many speakers each saying multiple utterances.
First there is a image-to-image translator $ G $ that takes an image from the X domain and transforms it to the $ Y $ domain. This generator consists of 3 convolutional layers followed by 9 residual convolutional layers for an encoder then 2 deconvolutions followed by a convolution to get the final image. We then define an adversarial loss at this stage. $ G $ is generating images from an image in $ X $ to look similar to other images in $ Y $ while $ D_Y $ tries to discriminate real images in $ Y $ from fake images generated by the generator G. This discriminator was 5 conv layers followed by 3 fully connected layers. This adversarial loss is defined as
$$ L(G, D_Y, X, Y) = \textbf{E}(\log(D_Y(y))) + \mathbb{E}(\log(1 - D_Y(G(x))) $$
And of course we want the same loss to be defined for the other direction from $ Y $ to $ X $ using generator $ F $ and discriminator $ D_X $. Next we want to incorporate the Cycle Consistency loss. This loss will simply be defined as the difference between the twice transformed sample $ x $, $ F(G(x)) $ and the original sample $ x $. The same will be defined the other way with the difference between $ G(F(y)) $ and $ y $. This gives an overall loss of:
$$ L(G, F, D_X, D_Y) = \mathbb{E}(\log(D_Y(y))) + \mathbb{E}(\log(1 - D_Y(G(x)))) \\ + \mathbb{E}(\log D_X(x)) + \mathbb{E}(\log(1 - D_X(G(y)))) \\ + \lambda(\mathbb{E}(\lVert F(G(x)) - x \rVert _1) + \mathbb{E}(\lVert G(F(y)) - y \rVert _1)) $$
Where lambda controls the importance of the cycle consistency loss. In the inference stage of the model we remove the extra padding inserted before and use the Giffin Lim algorithm as an audio reconstruction technique.
While this model has been used extensively for image processing tasks, as far as we know, this is the first time the model has been applied to the audio domain. After training the model for almost 2 days we got some results. Something interesting we noticed that later iterations of the model produced noisy audio samples. Below the results are shown:
Despite the results sounding somewhat robotic they provided a reasonable baseline. Furthermore, this is a significant improvement over any other approach relying solely on spectrograms that we have seen so far. Generally, we were surprised by how good the results turned out. We adapted the image processing CycleGAN model and applied it to two large collections with a lot of variability. Results are grainy as there is now unifying speech content however, there is a perceivable pitch change between genders.
Our main takeaways were the following:
- It is hard to train between collections of speech with so much internal phonetic variety and only pitch in common
- Working in the frequency domain can be good for when you are looking at cyclic behavior in signals and not so much for speech. We needed to move forward from our baseline handling the full scope of the audio data or at least use preprocessing that resulted in features with a time dimension. Using a standard image processing pipeline was expectedly not working great. It was time to turn to speech specific networks.
Supervised Speech Recognition + Speech Synthesis
Moving on from the baseline, we were thinking of models that processed audio in the time domain. We wanted to maintain our goal of finding a latent space and would continue working with encoder-decoder style models. Based on encouragement from Prof. Lim and Shao-Hua we decided to try out some supervision on the latent space and use a speech recognition encoder that would take MFCCs of audio (audio features) and classify the phonemes. This latent space of phonemes was then used to synthesize speech using Highway Net and CBHG modules from Tacotron. This decoder processed the phoneme distribution from the encoder and produced a spectrogram. Griffin-Lim reconstruction was used the synthesize audio back from the spectrogram. Our supervised speech model relied on recent developments in Speech Synthesis and adapted the speech recognition and speech synthesis pipeline in Tensorflow [11] from results on a Reddit post [12]

For a supervised latent space, we would definitely need a dataset with frame labeled phonemes, so we looked to TIMIT [13] for a large corpus of labeled audio data. The audio sampling rate was 16kHz and window length was 25 ms with a hop length of 5 ms. The MFCC features for speech recognition were generated for each window of the specified length shifting over by the hop length. The window length should fit a phoneme and 20-40 ms is around standard for audio models. The encoder was a Pre-net, CBHG module, and a dense and softmax layer for linear projection. The decoder was two CBHG + dense layer modules (details available in repo). Initially, there were bits of implementation details and adaptations that we struggled with, but we eventually trained the model on a variety of datasets including and played around with editing the decoder model to produce better, more human sounding results from the phonemes. The following results are after training for ~20k iterations on the TIMIT dataset for speech recognition and the female speaker from the Arctic dataset for speech synthesis as well as speakers from the VCTK dataset.
To evaluate the performance of our approach mean opinion score (MOS) tests were conducted. In the MOS tests, after listening to each stimulus (converted audio), the subjects were asked to rate the quality of each stimulus once for how recognizably male and once for how recognizably female the stimulus sounded, in a six-point Likert scale score from 0 to 5 where ‘0’ corresponded to the subjects sure the stimulus was not a human male/female voice and ‘5’ corresponded to the subjects being sure the stimulus was a human male/female voice. The chart shows the MOS gathered. For every sample (M2F - male to female conversion; F2M - female to male conversion) the scores highlight that most subjects agreed the converted audio clips sounded like the intended target.
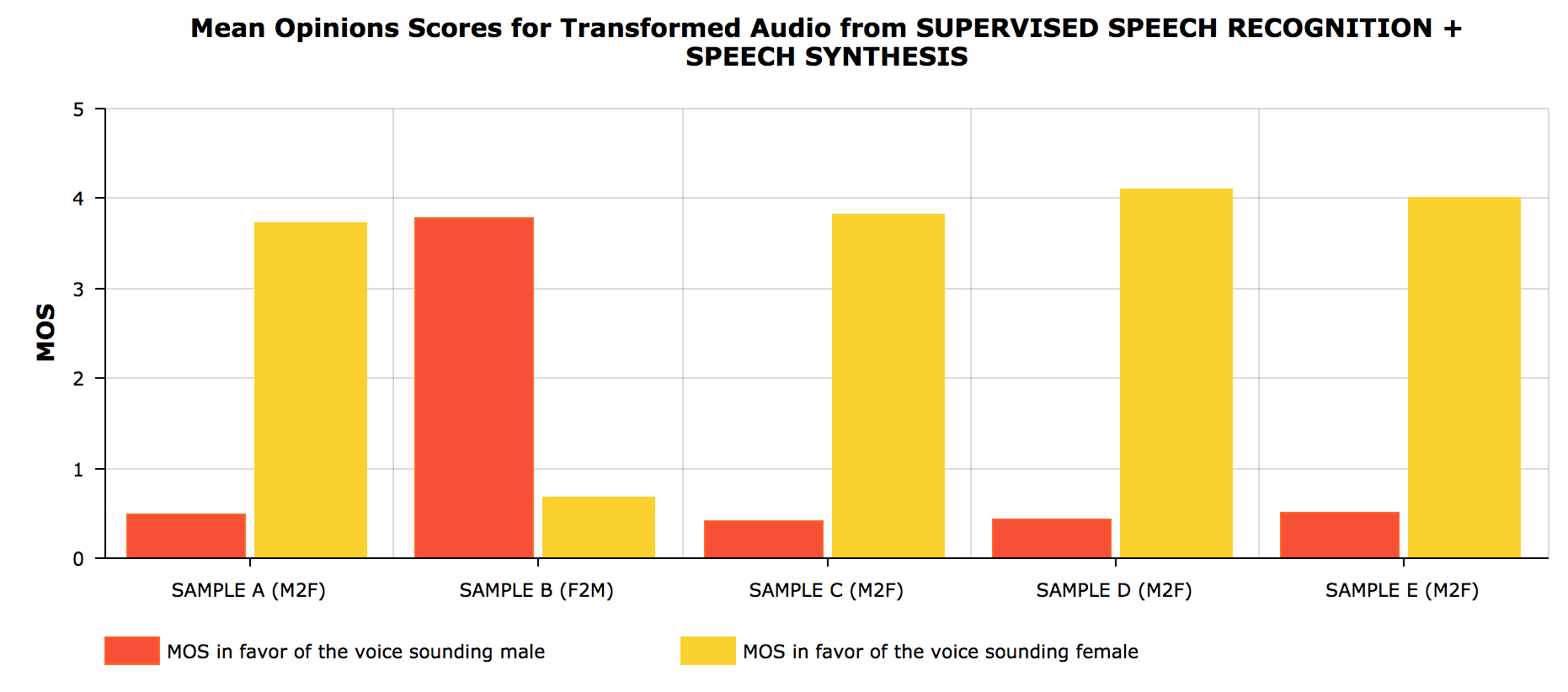
The results are more human sounding than those from the CycleGAN but are still a bit grainy and machine like. There is definitely a distinction between the generated audio from different style speakers and the model seems robust to input from different sources. We were able to casually throw in some of our speech and as a result, believe that the encoder is well trained and the decoder needs work or more features in the latent space. The phonemes are labeled, so the latent space is guaranteed to be something valuable and there is no fear of posterior collapse. Additionally, lots of data from the style speaker is used to train individual speech synthesis decoders. We wanted to be able to use one comprehensive decoder that was able to incorporate speaker information. As a result, in the next approach, we try to condition the decoders on the speaker id.
Speaker-informed (weakly supervised) VAE
Variational Auto-encoder (VAE) have achieved great success as a deep generative model for images. However, using them directly to model speech and encode any relevant information in the latent space has been proven difficult, due to the varying length of speech utterances. For example, in the context of voice conversion, the problem at hand, the content audio and the style audio can be of different lengths, rendering direct application of VAE or any standard auto-encoder architectures useless. Hence, we based our approach on using VAE along with an inherent alignment technique (parallel data not required) on features extracted from the speech utterances, namely spectrogram (513-dim), pitch (1-dim) and aperiodicity (513-dim)—features deemed useful for traditional speech synthesis methods. We adapted a VAE-based voice conversion algorithm by Hsu et. al. [14]. In this method, we formulate voice conversion as a controlled self-reconstruction problem. The algorithm first encodes the speech $ \mathbf{x}_n $ into a latent space $ \mathbf{z}_n $ without considering the speaker identity. This requires training on the same speech content spoken by different speakers in order to reconstruct one from another. So the encoding looks like:
$$ \mathbf{z}_n = f_{\phi} (\mathbf{x}_n) $$
Next, the speaker identity is encoded as a one-hot vector $ \mathbf{y}_n $ and appended to the latent space and the joint vector is used by the decoder to reconstruct the features of the original audio which are speaker-dependent.
$$\mathbf{\hat{x}}_n = f_{\theta}(\mathbf{z}_n, \mathbf{y}_n)$$
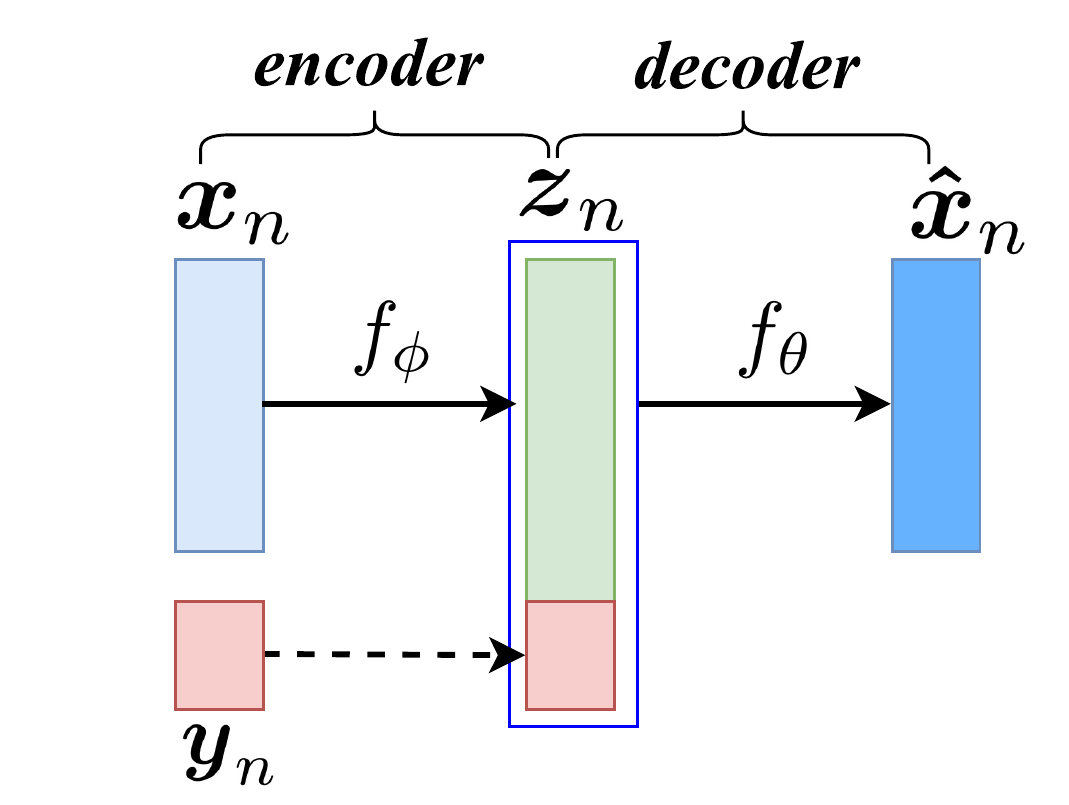
The encoder and decoder each consisted of 2 fully connected feed forward layers with 512 nodes and followed by a ReLU activation (except at the output). The latent space dimensionality was 64.
The loss function comprises of two terms–the regular VAE loss comprising of the joint log-likelihood of the reconstructed audio and the KL divergence in the latent space. In addition, we attempted to make the decoder learn the learning speaker-specific characteristics by introducing another conditional log-likelihood term: $ \log(p_{\theta}(\mathbf{x}_n \vert \mathbf{y}_n)) $. Our approach differs from the original paper (Hsu’s approach) in this way.
This loss function is intractable for direct optimization and hence its variational lower bound is maximized. One should also note that it is a weakly supervised approach, where transcript is not required, even phoneme-to-phoneme prior alignment is not required between two speakers. However, this relies on presence of training data consisting of same speech by multiple speakers (as in VCTK), and hence is not fully unsupervised approach.
We got decent results with this approach. Some examples are included below where:
Inspired by the great success of Wavenet, we also attempted to use frame-level raw audio representation in the input of VAE. In other words, instead of using spectrogram and other features extracted from the audio, we wanted to capture more long term temporal information modeled through a generative model for a raw audio. We were hoping that unconditioned Wavenet will be suitable for that. So we took two approaches:
- We used pretrained 3 stacked dilated causal convolutional layers (from Wavenet) as feature extractors and generated 128 ‘feature’ samples from each audio and fed them as input $ \mathbf{x}_n $ to the network. Similarly the same Wavenet is used for generation of the audio.
- We added 3 stacked dilated causal convolutional layers before encoder and after decoder and jointly train them together with the main VAE parameters.
However, none of these approaches worked satisfactorily as of now. More on this will be discussed in a later section.
All the approaches mentioned in this section heavily relied on modeling speaker characteristics from ample, albeit unaligned audio content from each of the speakers. This is a limitation since ideally for voice conversion, we would want to learn the speaker characteristics of the style audio input without any prior audio from that speaker. Hence we wanted to explore unsupervised architectures.
Unsupervised Autoencoders (VQ-VAE)
The ideal setup for our network architecture is to learn an embedding for a speaker style in a unsupervised way. The generator should produce the final stylized voice by taking the content audio as input while being conditioned on the speaker style embedding. At first, we were thinking the ideal way to implement such a system would be to use a VAE to learn the embedding of each speaker. An important aspect would be to use an encoder and decoder in the VAE suited for audio processing, which we believed to be some variant of Wavenet.
Once the style embedding has been learned for each speaker, the next step is apply the style to content audio. An autoregressive Wavenet decoder on the raw content audio while conditioning on the style speaker ID and style embedding could potentially generate high quality stylized audio. The Wavenet generator would be trained on all of the audio samples where the target is the audio sample and the network is globally conditioned on the content speaker ID and locally conditioned on the embedding for the content speaker that generated that sample. Globally conditioned just means that the feature is added to every possible hidden node of the Wavenet. On the other hand local conditioning is for more temporally variant features and are added to upsampled nodes only. Below is an image displaying global conditioning. Local conditioning would have arrows only going to the higher up nodes. Global conditioning on style speaker ID while locally conditioning on the content speaker embedding should logically result in maintaining phonetic content while converting a content audio source to a style speaker.
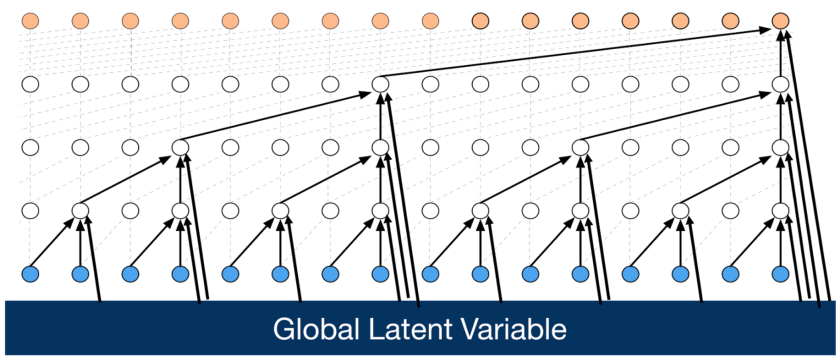
Implementing all of this was a very daunting task as there is not an clear implementation for an audio VAE and there is not an existing implementation of locally conditioned wavenets. Before we were about to get started on implementing much of this on our own, we came across a paper in this space that seemed promising and decided to pursue it instead.
This promising avenue is a very recent publication (this month) by Deepmind [15] for a Vector Quantised-Variational AutoEncoder (VQ-VAE) that applies Vector Quantization on the latent space to prevent posterior collapse, where latents are ignored due to an autoregressive decoder (model that uses prediction from previous state to generate next state like Wavenet). Vector quantization on the latent space involves simply mapping the output of the encoder to the nearest point in the embedding space. The Vector Quantization is another modification done to the latent space like the KL Divergence loss in Variational Autoencoders to ensure that the latent vectors follow a unit gaussian distribution and sampling from that space to generate outputs becomes easier. There appears to be a lot of potential advancements in algorithms for supervision and control over latent spaces in autoencoders.
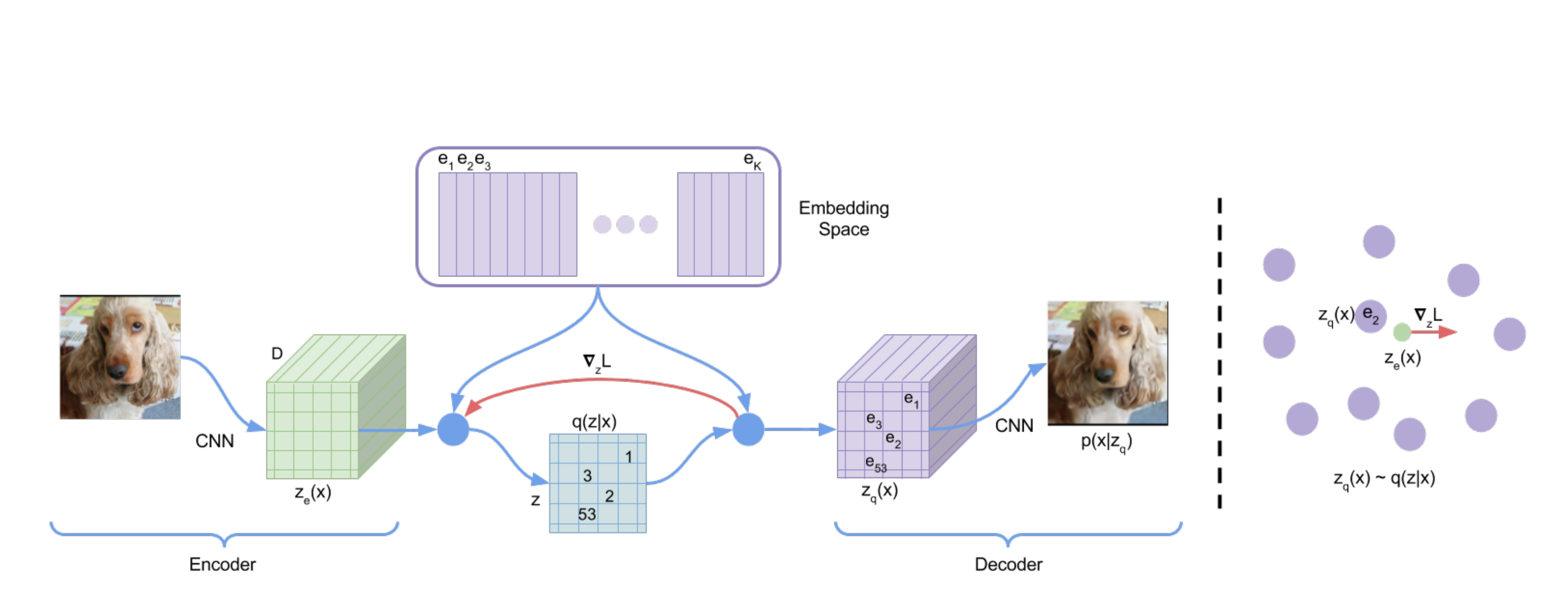
The trained latent space on audio appears to mimic phonemes even without the supervision achieved previously in our second approach. To be honest, we really didn’t know how this method works really well, so we were eager to try it out. As always, Deepmind famously left the implementation of the architecture to the community. A lot of necessary details about the audio architecture were left out in the paper. In the past two weeks, we have taken starting implementations of the VQ-VAE architecture for images and ripped out the convolutional decoder for a Wavenet decoder that is conditioned on the latent space produced by the encoder. We also had to make adjustments to how the input processing was handled as Wavenet models process audio in the time domain using mu-law encoding and discretize audio into one-hot vectors for each time sample, becoming a 256 x T matrix, where T is the number of time samples. We even tried the implementation from two angles, adapting a VAE architecture and a Wavenet autoencoder architecture. We have had a lot of problems in training these models as they often diverge while training.
Despite working hard for a long time we were unable to get this model to train. The parameter update would always evaluate to NaN, making the loss NaN. This originally occurred in our first approach of just substituting the encoder with trying to implement what was described in the paper and a Wavenet decoder also as described in the paper. After this approach resulted in NaN loss we thought the issue might be with how we implemented the encoder or decoder. Eventually we realized that NSynth had the same format of finding a latent space for style in an unsupervised fashion using a VAE with a Wavenet encoder and decoder. NSynth is a project by Google that combines the sounds of two instruments into one. We adopted this same architecture and then substituted in the vector quantization code. Even after that we kept getting NaN losses. Our final idea was that our vector quantization code was incorrect so we just used the standard NSynth architecture but still got NaN losses. This led us to believe that the issue was in how we were inputting the data into the network. We followed the same processing of mu-law encoding for the voice data and that was the only difference between our approach and using NSynth on instrument sounds. In the end we were not able to find out how the paper by Deepmind was able to solve this problem and produce those results. However, we are still hopeful and are working towards a result.
With a trained latent space that mimics phonemes from the VQ-VAE, we hope to try out algorithms like neural style where backpropagation is performed on inputs with respect to the loss in some feature activations. Being able to change other features in the audio signal while keeping phoneme loss down would be crucial to voice conversion. Additionally, unsupervised models trained on large datasets tend to be more robust and are closer to how we learn. At the same time, the high level features that they learn might be some abstraction beyond what we would be capable of producing and supervising such as if they extracted meta phonemes or something beyond our knowledge of phonetics and linguistics.
Lessons Learned
There is definitely a lot of work to be done in the meaningful latent space representation for raw audio and we hope to be part of the effort in trying to understand this complex domain. Audio should definitely not be treated like images with corresponding image algorithms often tend to update input signals based on correlations in features. We do believe, however, that given a powerful enough latent space like the one that claims to mimic phonemes in the VQ-VAE, cool algorithms similar to the neural style algorithm can be developed for audio to make use of that space. In addition to voice conversion, one can even think of making ‘emotion’ transfer–for example, literally “take a sad song and make it happier”, without changing the textual content.
While this whole report so far has been been a distillation of the lessons we have learned from each prospective approach, we overall learned that audio style transfer is a difficult problem that takes a difficult model to design and train. In the end we believe we had the right theoretical idea for how to achieve good results with audio style transfer, and the recent paper from Deepmind confirms that. However, we were unable to get implement this network correctly in the limited timeframe as it simply would not train.
The spectrogram approaches with CycleGAN worked better than we thought. There was a clear transformation from male to female but the results sounded noisy and robotic. The supervised speech recognition worked better, however, the amount of supervision needed in this approach and the fact that phoneme data was needed to construct the embedded layer and decoder could only transfer one speaker style at a time made the system undesirable. The results sounded robotic but less noisy than spectrogram approaches. Next, the speaker informed VAE did about as well as the supervised speech recognition approach, although the generated audio files sounded less natural. Finally, the VQ-VAE approach proved to be too difficult for us to actually train correctly. Overall, all of these approaches taught us that audio is difficult to deal with. Furthermore, implementing the exact networks used in papers is difficult when many of the implementation details are left out.
On a more personal level, all of us became very familiar with in depth usage of TensorFlow, audio processing (Giffin Lim, mu-encoding, spectrograms, etc), CycleGAN, WaveNet (as we had to implement conditioning on top of WaveNet on our own and figure out how to use Wavenet as an encoder / decoder) and a more in depth look into VAEs (with having to implement VQ-VAE and this whole project being about finding an embedding). We also got used to using cloud computing (and even have a script for setting gce up https://github.com/ASzot/voice-conversion/blob/master/setup_gce.sh ).
Contributions
All the source code is avaliable in the link above (https://github.com/ASzot/voice-conversion ). We all read a lot of papers for potential avenues, had many productive discussions among ourselves and wrote sections of the blog and presentation regarding sections that we worked on.
- Andrew - Implemented the baseline CycleGAN for audio data and implemented the VQ-VAE model. Investigated how to use Wavenet as an encoder and condition on an embedding for the decoder.
- Sriram - Worked on developing models with a supervised latent space and unconditional generator as well as implementing the VQ-VAE model. Helped a bit with our CycleGAN implementation between female and male audio.
- Nasir - Trained speaker-informed VAE model after implementing the modified loss function. Also explored and implemented speaker-informed VAE models based on Wavenet-generated input.
- Arshdeep - Evaluated effectiveness of original Wavenet Model (by DeepMind) for style transfer task. Collected and generated Mean-Opinion Scores based on human evaluation of produced audio from the various models. Created cool Style Transfer graphic.
Sources
- https://arxiv.org/pdf/1705.04058.pdf
- https://arxiv.org/pdf/1703.10135.pdf
- https://arxiv.org/pdf/1609.03499.pdf
- https://magenta.tensorflow.org/nsynth
- https://medium.com/@juliendespois/latent-space-visualization-deep-learning-bits-2-bd09a46920df
- http://homepages.inf.ed.ac.uk/jyamagis/page3/page58/page58.html
- https://catalog.ldc.upenn.edu/ldc93s1
- https://dmitryulyanov.github.io/audio-texture-synthesis-and-style-transfer/
- https://arxiv.org/pdf/1703.10593.pdf
- https://github.com/librosa/librosa
- https://github.com/andabi/deep-voice-conversion
- https://www.reddit.com/r/MachineLearning/comments/7a0wcv/p_voice_style_transfer_speaking_like_kate_winslet/
- https://catalog.ldc.upenn.edu/ldc93s1
- https://arxiv.org/pdf/1610.04019.pdf
- https://arxiv.org/abs/1711.00937